Úpravy znakových polí
Situace: Nedaří se spojení dvou databází
Software IDEA nabízí, jako jednu ze základních funkcí, volbu „Spojit“ (karta Analýza -> Propojit -> Spojit). Funkce je založena na principu, že pokud existují dvě databáze mající alespoň jedno shodné pole – „klíčové pole“, lze data z těchto dvou databází, na základě libovolného klíčového pole, spojovat k sobě. Stěžejní pro správnou funkčnost volby „Spojit“ je právě absolutní shoda klíčových polí ve dvou databázích tzn., že existuje citlivost na velká, malá písmena, mezery či další znaky; tato uvedená skutečnost však může způsobit v některých případech problémy – spojovaná data většinou pochází z různých zdrojů, což může způsobit popsané rozdíly, kdy každý software může vkládat jinak mezery, velká či malá písmena apod.
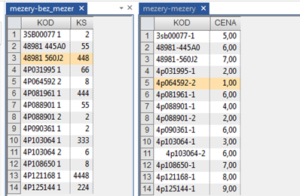
Ukázku můžete vidět na Obr. č.1. v poli „KOD“
Řešení
Jak již bylo výše nastíněno, v tomto T&T se zaměříme na úpravy znakových polí tak, aby bylo možno spojit dvě databáze. Při pohledu na Obr. č. 1, který zobrazuje dvě databáze, z nichž jedna udává počet výrobku a druhá cenu, je při pohledu na pole „KOD“ patrných hned několik problémů:
- liší se oddělovač – v jednom případě jde o mezeru, ve druhém o pomlčku. V řádku č. 11 jsou vloženy počáteční mezery.
- liší se velikost písmen v obou databázích
Aby byly výše zobrazené databáze „spojitelné“, je zapotřebí popsané rozdíly odstranit a klíčová pole „KOD“ sjednotit. Dále si tedy popíšeme funkce, které mohou být v těchto případech užitečné.
ad1. problém mezer se může vyskytnout a nemusí být na první pohled ani patrný tak, jako je zobrazeno na Obr. č. 1. Mezery nemusí být viditelné a většinou na tento problém uživatel narazí až poté, co poprvé spustí funkci „Spojit“ (či „Sumarizovat“) – ve výsledné databázi jsou pak na první pohled stejné hodnoty, které však nebyly spárovány do jednoho řádku; tato chyba často značí problém mezer či jiných „neviditelných“ znaků (např. také pevná mezera). Existenci mezer lze ověřit volbou „Zvýraznit mezery“ na kartě „Analýza“. Volba „zvýraznit mezery“ však zvýrazní pouze standardní mezery, nikoliv tzv. pevné mezery či jiné znaky, které se na první pohled jako mezery tváří (viz Obr. č.2. a vlevo zvýrazněné mezery, v databázi vpravo již nikoliv).
Jedná-li se tedy o „klasickou“ mezeru, lze jejího odstranění dosáhnout funkcí @Trim. Funkce @Trim má několik variant:
- @AllTrim – odstraní vedoucí a koncové mezery
- @L Trim – odstraňuje počáteční mezery
- @Trim – odstraňuje pouze koncové mezery
V tomto případě se však nejedná ani o koncové, ani o počáteční mezery, proto je potřeba použít funkci, která se postará o „radikálnější“ úpravu, a to funkci
- @Strip – tato funkce odstraní veškeré mezery, kdekoliv se v daném znakovém řetězci vyskytují a dále odstraní veškerou interpunkci a další znaky, přičemž ponechá jen číslice a písmena
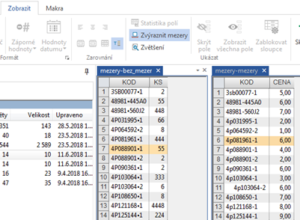
Obr. č. 2: mezery jsou zvýrazněny tečkou
ad2. rozdílná velikost písmen, která je též překážkou pro korektní spojení dvou databázi, lze odstranit poměrně snadno aplikací funkce
- @Upper – všechna písmena změní na velká nebo
- @Lower – všechna písmena konvertuje na malá
Aplikujeme-li na zobrazené databáze rovnici složenou z výše uvedených funkcí
@Upper(@Strip(KOD))
a vytvoříme nové pole KOD_UPRAVA, dostaneme výsledek, jak je zobrazen na Obr.č. 3
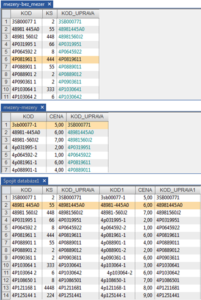
Obr. č. 3: databáze s upravenými poli „KOD“ a následně dle tohoto pole spojené
Závěr
Funkce „Spojit“, „Porovnat“ případně „Vizuální spojení“ vyžadují pro korektní propojení databází shodná klíčová pole. Jednou z možností, kterou lze využít, neprobíhá-li propojování korektně, jsou právě výše uvedené postupy a funkce.